原文:

报错了,
在Linux系统中,/usr/include/ 是C/C++等的头文件放置处,
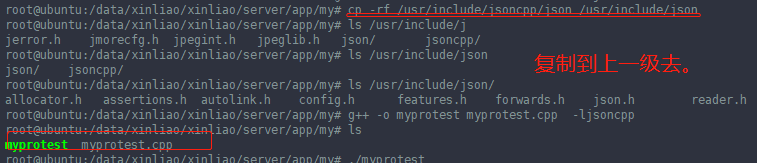
-------------------------------------------------------
1.简述
-
互联网上充斥着各种各样的网络服务,在对外提供网络服务时,服务端和客户端需要遵循同一套数据通讯协议,才能正常的进行通讯;就好像你跟台湾人沟通用闽南语,跟广东人沟通就用粤语一样。
-
实现自己的应用功能时,已知的知名协议(http,smtp,ftp等)在安全性、可扩展性等方面不能满足需求,从而需要设计并实现自己的应用层协议。
2.协议分类
2.1按编码方式
-
二进制协议
比如网络通信运输层中的tcp协议。 -
明文的文本协议
比如应用层的http、redis协议。 -
混合协议(二进制+明文)
比如苹果公司早期的APNs推送协议。
2.2按协议边界
-
固定边界协议
能够明确得知一个协议报文的长度,这样的协议易于解析,比如tcp协议。 -
模糊边界协议
无法明确得知一个协议报文的长度,这样的协议解析较为复杂,通常需要通过某些特定的字节来界定报文是否结束,比如http协议。
3.协议优劣的基本评判标准
-
高效的
快速的打包解包减少对cpu的占用,高数据压缩率降低对网络带宽的占用。 -
简单的
易于人的理解、程序的解析。 -
易于扩展的
对可预知的变更,有足够的弹性用于扩展。 -
容易兼容的
-
向前兼容,对于旧协议发出的报文,能使用新协议进行解析,只是新协议支持的新功能不能使用。
-
向后兼容,对于新协议发出的报文,能使用旧协议进行解析,只是新协议支持的新功能不能使用。
-
4.自定义应用层协议的优缺点
4.1优点
-
非知名协议,数据通信更安全,黑客如果要分析协议的漏洞就必须先破译你的通讯协议。
-
扩展性更好,可以根据业务需求和发展扩展自己的协议,而已知的知名协议不好扩展。
4.2缺点
-
设计难度高,协议需要易扩展,最好能向后向前兼容。
-
实现繁琐,需要自己实现序列化和反序列化。
5.动手前的预备知识
5.1大小端
计算机系统在存储数据时起始地址是高地址还是低地址。
-
大端
从高地址开始存储。 -
小端
从低地址开始存储。 -
图解

-
判断
这里以c/c++语言代码为例,使用了c语言中联合体的特性。
#include#include using namespace std; bool bigCheck() { union Check { char a; uint32_t data; }; Check c; c.data = 1; if (1 == c.a) { return false; } return true; } int main() { if (bigCheck()) { cout << "big" << endl; } else { cout << "small" << endl; } return 0; }
5.2网络字节序
顾名思义就是数据在网络传送的字节流中的起始地址的高低,为了避免在网络通信中引入其他复杂性,网络字节序统一是大端的。
5.3本地字节序
本地操作系统的大小端,不同操作系统可能采用不同的字节序。
5.4内存对象与布局
任何变量,不管是堆变量还是栈变量都对应着操作系统中的一块内存,由于内存对齐的要求程序中的变量并不是紧凑存储的,例如一个c语言的结构体Test在内存中的布局可能如下图所示。

struct Test{ char a; char b; int32_t c; }; 5.5序列化与反序列化
-
将计算机语言中的内存对象转换为网络字节流,例如把c语言中的结构体Test转化成uint8_t data[6]字节流。
-
将网络字节流转换为计算机语言中的内存对象,例如把uint8_t data[6]字节流转化成c语言中的结构体Test。

6.一个例子
6.1 协议设计
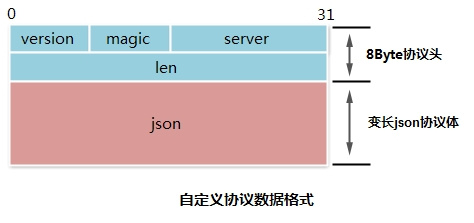
本协议采用固定边界+混合编码策略。
-
协议头
8字节的定长协议头。支持版本号,基于魔数的快速校验,不同服务的复用。定长协议头使协议易于解析且高效。 -
协议体
变长json作为协议体。json使用明文文本编码,可读性强、易于扩展、前后兼容、通用的编解码算法。json协议体为协议提供了良好的扩展性和兼容性。 -
协议可视化图
6.2 协议实现
talk is easy,just code it,使用c/c++语言来实现。
6.2.1c/c++语言实现
-
使用结构体MyProtoHead来存储协议头
-
/* 协议头 */struct MyProtoHead{ uint8_t version; //协议版本号 uint8_t magic; //协议魔数 uint16_t server; //协议复用的服务号,标识协议之上的不同服务 uint32_t len; //协议长度(协议头长度+变长json协议体长度) }; -
使用开源的Jsoncpp类来存储协议体
-
协议消息体
-
/* 协议消息体 */struct MyProtoMsg{ MyProtoHead head; //协议头 Json::Value body; //协议体 }; -
打包类
-
/* MyProto打包类 */class MyProtoEnCode{public: //协议消息体打包函数 uint8_t * encode(MyProtoMsg * pMsg, uint32_t & len); private: //协议头打包函数 void headEncode(uint8_t * pData, MyProtoMsg * pMsg); }; -
解包类
-
code is easy,just run it.
typedef enum MyProtoParserStatus{ ON_PARSER_INIT = 0, ON_PARSER_HAED = 1, ON_PARSER_BODY = 2, }MyProtoParserStatus; /* MyProto解包类 */ class MyProtoDeCode { public: void init(); void clear(); bool parser(void * data, size_t len); bool empty(); MyProtoMsg * front(); void pop(); private: bool parserHead(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak); bool parserBody(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak); private: MyProtoMsg mCurMsg; //当前解析中的协议消息体 queuemMsgQ; //解析好的协议消息队列 vector mCurReserved; //未解析的网络字节流 MyProtoParserStatus mCurParserStatus; //当前解析状态 }; 6.2.2打包(序列化)
void MyProtoEnCode::headEncode(uint8_t * pData, MyProtoMsg * pMsg){ //设置协议头版本号为1 *pData = 1; ++pData; //设置协议头魔数 *pData = MY_PROTO_MAGIC; ++pData; //设置协议服务号,把head.server本地字节序转换为网络字节序 *(uint16_t *)pData = htons(pMsg->head.server); pData += 2; //设置协议总长度,把head.len本地字节序转换为网络字节序 *(uint32_t *)pData = htonl(pMsg->head.len); } uint8_t * MyProtoEnCode::encode(MyProtoMsg * pMsg, uint32_t & len) { uint8_t * pData = NULL; Json::FastWriter fWriter; //协议json体序列化 string bodyStr = fWriter.write(pMsg->body); //计算协议消息序列化后的总长度 len = MY_PROTO_HEAD_SIZE + (uint32_t)bodyStr.size(); pMsg->head.len = len; //申请协议消息序列化需要的空间 pData = new uint8_t[len]; //打包协议头 headEncode(pData, pMsg); //打包协议体 memcpy(pData + MY_PROTO_HEAD_SIZE, bodyStr.data(), bodyStr.size()); return pData; }6.2.3解包(反序列化)
bool MyProtoDeCode::parserHead(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak) { parserBreak = false; if (curLen < MY_PROTO_HEAD_SIZE) { parserBreak = true; //终止解析 return true; } uint8_t * pData = *curData; //解析版本号 mCurMsg.head.version = *pData; pData++; //解析魔数 mCurMsg.head.magic = *pData; pData++; //魔数不一致,则返回解析失败 if (MY_PROTO_MAGIC != mCurMsg.head.magic) { return false; } //解析服务号 mCurMsg.head.server = ntohs(*(uint16_t*)pData); pData+=2; //解析协议消息体的长度 mCurMsg.head.len = ntohl(*(uint32_t*)pData); //异常大包,则返回解析失败 if (mCurMsg.head.len > MY_PROTO_MAX_SIZE) { return false; } //解析指针向前移动MY_PROTO_HEAD_SIZE字节 (*curData) += MY_PROTO_HEAD_SIZE; curLen -= MY_PROTO_HEAD_SIZE; parserLen += MY_PROTO_HEAD_SIZE; mCurParserStatus = ON_PARSER_HAED; return true; } bool MyProtoDeCode::parserBody(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak) { parserBreak = false; uint32_t jsonSize = mCurMsg.head.len - MY_PROTO_HEAD_SIZE; if (curLen < jsonSize) { parserBreak = true; //终止解析 return true; } Json::Reader reader; //json解析类 if (!reader.parse((char *)(*curData), (char *)((*curData) + jsonSize), mCurMsg.body, false)) { return false; } //解析指针向前移动jsonSize字节 (*curData) += jsonSize; curLen -= jsonSize; parserLen += jsonSize; mCurParserStatus = ON_PARSER_BODY; return true; } bool MyProtoDeCode::parser(void * data, size_t len) { if (len <= 0) { return false; } uint32_t curLen = 0; uint32_t parserLen = 0; uint8_t * curData = NULL; curData = (uint8_t *)data; //把当前要解析的网络字节流写入未解析完字节流之后 while (len--) { mCurReserved.push_back(*curData); ++curData; } curLen = mCurReserved.size(); curData = (uint8_t *)&mCurReserved[0]; //只要还有未解析的网络字节流,就持续解析 while (curLen > 0) { bool parserBreak = false; //解析协议头 if (ON_PARSER_INIT == mCurParserStatus || ON_PARSER_BODY == mCurParserStatus) { if (!parserHead(&curData, curLen, parserLen, parserBreak)) { return false; } if (parserBreak) break; } //解析完协议头,解析协议体 if (ON_PARSER_HAED == mCurParserStatus) { if (!parserBody(&curData, curLen, parserLen, parserBreak)) { return false; } if (parserBreak) break; } if (ON_PARSER_BODY == mCurParserStatus) { //拷贝解析完的消息体放入队列中 MyProtoMsg * pMsg = NULL; pMsg = new MyProtoMsg; *pMsg = mCurMsg; mMsgQ.push(pMsg); } } if (parserLen > 0) { //删除已经被解析的网络字节流 mCurReserved.erase(mCurReserved.begin(), mCurReserved.begin() + parserLen); } return true; }7.完整源码与测试
#include#include #include #include #include #include #include #include using namespace std; const uint8_t MY_PROTO_MAGIC = 88; const uint32_t MY_PROTO_MAX_SIZE = 10 * 1024 * 1024; //10M const uint32_t MY_PROTO_HEAD_SIZE = 8; typedef enum MyProtoParserStatus { ON_PARSER_INIT = 0, ON_PARSER_HAED = 1, ON_PARSER_BODY = 2, }MyProtoParserStatus; /* 协议头 */ struct MyProtoHead { uint8_t version; //协议版本号 uint8_t magic; //协议魔数 uint16_t server; //协议复用的服务号,标识协议之上的不同服务 uint32_t len; //协议长度(协议头长度+变长json协议体长度) }; /* 协议消息体 */ struct MyProtoMsg { MyProtoHead head; //协议头 Json::Value body; //协议体 }; void myProtoMsgPrint(MyProtoMsg & msg) { string jsonStr = ""; Json::FastWriter fWriter; jsonStr = fWriter.write(msg.body); printf("Head[version=%d,magic=%d,server=%d,len=%d]\n" "Body:%s", msg.head.version, msg.head.magic, msg.head.server, msg.head.len, jsonStr.c_str()); } /* MyProto打包类 */ class MyProtoEnCode { public: //协议消息体打包函数 uint8_t * encode(MyProtoMsg * pMsg, uint32_t & len); private: //协议头打包函数 void headEncode(uint8_t * pData, MyProtoMsg * pMsg); }; void MyProtoEnCode::headEncode(uint8_t * pData, MyProtoMsg * pMsg) { //设置协议头版本号为1 *pData = 1; ++pData; //设置协议头魔数 *pData = MY_PROTO_MAGIC; ++pData; //设置协议服务号,把head.server本地字节序转换为网络字节序 *(uint16_t *)pData = htons(pMsg->head.server); pData += 2; //设置协议总长度,把head.len本地字节序转换为网络字节序 *(uint32_t *)pData = htonl(pMsg->head.len); } uint8_t * MyProtoEnCode::encode(MyProtoMsg * pMsg, uint32_t & len) { uint8_t * pData = NULL; Json::FastWriter fWriter; //协议json体序列化 string bodyStr = fWriter.write(pMsg->body); //计算协议消息序列化后的总长度 len = MY_PROTO_HEAD_SIZE + (uint32_t)bodyStr.size(); pMsg->head.len = len; //申请协议消息序列化需要的空间 pData = new uint8_t[len]; //打包协议头 headEncode(pData, pMsg); //打包协议体 memcpy(pData + MY_PROTO_HEAD_SIZE, bodyStr.data(), bodyStr.size()); return pData; } /* MyProto解包类 */ class MyProtoDeCode { public: void init(); void clear(); bool parser(void * data, size_t len); bool empty(); MyProtoMsg * front(); void pop(); private: bool parserHead(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak); bool parserBody(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak); private: MyProtoMsg mCurMsg; //当前解析中的协议消息体 queue mMsgQ; //解析好的协议消息队列 vector mCurReserved; //未解析的网络字节流 MyProtoParserStatus mCurParserStatus; //当前解析状态 }; void MyProtoDeCode::init() { mCurParserStatus = ON_PARSER_INIT; } void MyProtoDeCode::clear() { MyProtoMsg * pMsg = NULL; while (!mMsgQ.empty()) { pMsg = mMsgQ.front(); delete pMsg; mMsgQ.pop(); } } bool MyProtoDeCode::parserHead(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak) { parserBreak = false; if (curLen < MY_PROTO_HEAD_SIZE) { parserBreak = true; //终止解析 return true; } uint8_t * pData = *curData; //解析版本号 mCurMsg.head.version = *pData; pData++; //解析魔数 mCurMsg.head.magic = *pData; pData++; //魔数不一致,则返回解析失败 if (MY_PROTO_MAGIC != mCurMsg.head.magic) { return false; } //解析服务号 mCurMsg.head.server = ntohs(*(uint16_t*)pData); pData+=2; //解析协议消息体的长度 mCurMsg.head.len = ntohl(*(uint32_t*)pData); //异常大包,则返回解析失败 if (mCurMsg.head.len > MY_PROTO_MAX_SIZE) { return false; } //解析指针向前移动MY_PROTO_HEAD_SIZE字节 (*curData) += MY_PROTO_HEAD_SIZE; curLen -= MY_PROTO_HEAD_SIZE; parserLen += MY_PROTO_HEAD_SIZE; mCurParserStatus = ON_PARSER_HAED; return true; } bool MyProtoDeCode::parserBody(uint8_t ** curData, uint32_t & curLen, uint32_t & parserLen, bool & parserBreak) { parserBreak = false; uint32_t jsonSize = mCurMsg.head.len - MY_PROTO_HEAD_SIZE; if (curLen < jsonSize) { parserBreak = true; //终止解析 return true; } Json::Reader reader; //json解析类 if (!reader.parse((char *)(*curData), (char *)((*curData) + jsonSize), mCurMsg.body, false)) { return false; } //解析指针向前移动jsonSize字节 (*curData) += jsonSize; curLen -= jsonSize; parserLen += jsonSize; mCurParserStatus = ON_PARSER_BODY; return true; } bool MyProtoDeCode::parser(void * data, size_t len) { if (len <= 0) { return false; } uint32_t curLen = 0; uint32_t parserLen = 0; uint8_t * curData = NULL; curData = (uint8_t *)data; //把当前要解析的网络字节流写入未解析完字节流之后 while (len--) { mCurReserved.push_back(*curData); ++curData; } curLen = mCurReserved.size(); curData = (uint8_t *)&mCurReserved[0]; //只要还有未解析的网络字节流,就持续解析 while (curLen > 0) {